오늘 배운 건 에러 핸들링 + 재시도. 신뢰성·정확도를 갖춘 LLM 서비스를 운영하려면 가장 먼저 깔아야 할 인프라.
Table of contents
Open Table of contents
1. LLM API 에러는 4가지로 분류된다
내가 처리해야 할 에러는 다 같은 게 아니다. 원인 → 대응 방식 이 다르므로 먼저 분류.
일시적 에러 — 재시도하면 풀림
| 에러 | 의미 |
|---|---|
| RateLimitError (429) | 너무 빠르게 호출. 잠시 후 재시도 |
| APIConnectionError | 네트워크 일시 단절 |
| APITimeoutError | 응답이 너무 오래 걸림 |
| InternalServerError (500) | Anthropic 서버 일시 문제 |
→ 재시도 가치 있음.
영구 에러 — 재시도해봤자 의미 없음
| 에러 | 의미 |
|---|---|
| AuthenticationError (401) | API 키 잘못됨 |
| PermissionDeniedError (403) | 권한 없음 |
| BadRequestError (400) | 요청 형식 잘못됨 |
| NotFoundError (404) | 모델 이름 잘못됨 |
→ 코드 / 설정을 고쳐야 함. 재시도는 시간 낭비.
사용자 입력 관련
- 입력 토큰이 컨텍스트 윈도우 초과
- 위험한 내용으로 차단됨
→ 입력 단에서 사전 검증 / 사용자에게 다시 묻기.
응답 형식 관련 (LLM 자체 문제)
- JSON 을 요청했는데 JSON 이 아닌 걸 반환
- 도구 호출 인자가 스키마와 안 맞음
- 응답이 잘림 (
max_tokens도달)
→ 에러는 아니지만 형식이 어긋남. 추가 검증 + 재시도 필요.
2. 어떤 에러를 내가 처리해야 하는가
| 분류 | 처리 책임 |
|---|---|
| 영구 에러 | 거의 다 코드 잘못 — 처음부터 고치고 가야 함 |
| 사용자 입력 관련 | 입력 검증 / UX 처리 |
| 일시적 에러 | 내가 잘 처리해야 안정적 운영 가능 ✅ |
| 응답 형식 관련 | 내가 잘 처리해야 안정적 운영 가능 ✅ |
즉 일시적 에러 + 응답 형식 관련 이 내 책임. 이 두 가지를 어떻게 다루는지를 4단계 예제로 익혔다.
3. 1단계 — 기본 try-except 래퍼
실전에서는 래퍼 함수 를 만들어서 API 호출을 감싼다. 발견할 수 있는 에러 각각에 대해 except 를 걸고 처리:
- 일시적 에러 → 재시도 로직으로 보냄
- 영구 에러 → 어떤 에러인지 확실하게 출력 해서 코드 수정 용이하게
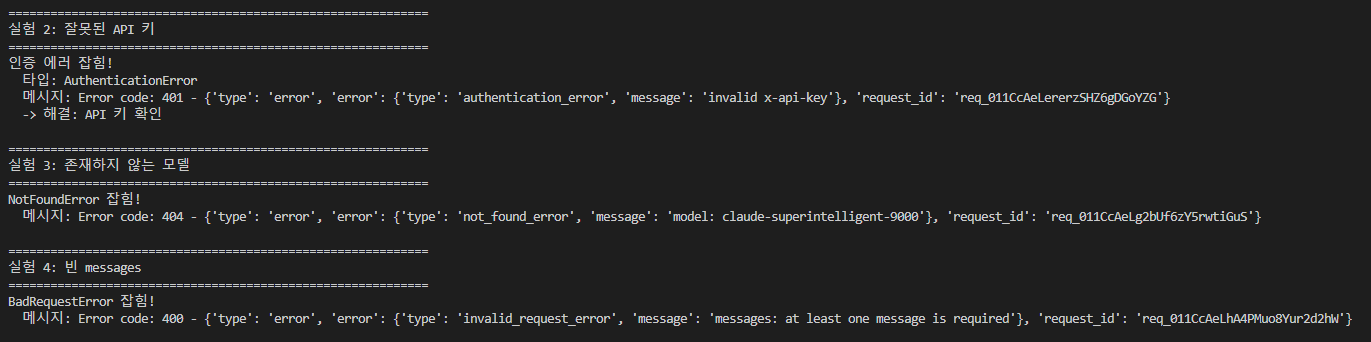
핵심은 “어떤 에러가 났는지 모호하게 두면 안 된다” 는 점. 디버깅이 안 되는 게 가장 큰 비용.
4. 2단계 — Exponential Backoff 재시도
일시적 에러일 때 재시도 패턴. 그냥 즉시 재시도하면 안 된다 — 같은 순간에 많은 클라이언트가 동시에 재시도해서 부하를 더 일으킬 수 있다 (“thundering herd” 문제).
해결책:
- 시도 횟수에 따라 대기 시간을 지수적으로 늘림 (1초 → 2초 → 4초 → 8초 …)
- Jitter (노이즈) 를 추가해 재시도 타이밍을 분산
이걸 Exponential Backoff with Jitter 패턴이라고 한다.
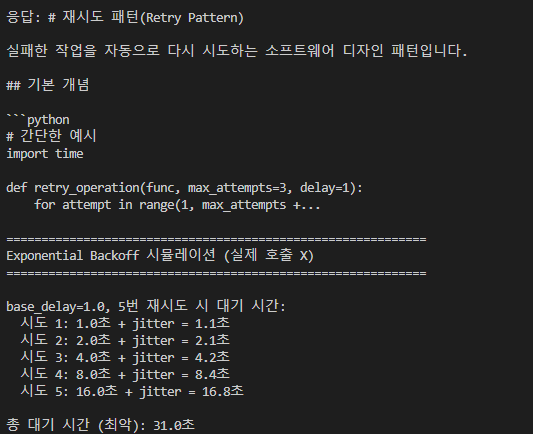
이 패턴은 LLM API 한정이 아니라 모든 외부 API 호출의 표준 이다. AWS SDK, Google Cloud SDK 등도 다 이 패턴을 쓴다.
5. 3단계 — Anthropic SDK 가 알아서 해주는 부분
수동으로 재시도 코드를 짤 수도 있지만, Anthropic SDK 가 기본으로 재시도를 해준다.
- 일시적 에러는 SDK 가 자동으로 재시도
- 영구 에러는 재시도하지 않음 (의미 없으니까)
- 위에서 만든 Exponential backoff 도 자동 적용
즉 간단한 호출이나 표준 에러 처리는 SDK 에 맡기면 된다.
수동 재시도 로직이 필요한 경우는 따로 있다:
- 특별한 재시도 로직 (예: 모델 변경, 프롬프트 수정 후 재시도)
- 재시도 사이에 추가 동작 (로그, 알림, 사용자 알림)
- N번 재시도 후 다른 처리 (fallback 응답, 캐시된 응답 반환 등)
이런 케이스에선 수동으로 짜야 한다.
6. 4단계 — JSON 응답 검증 (LLM 형식 위반 대응)
마지막은 에러는 아니지만 LLM 이 형식을 어긴 경우. JSON 으로 답하라고 했는데 다른 형식으로 줄 때, 어떻게 추적하고 다시 시도하게 할까.
내가 만든 검증 로직:
- LLM 응답에서 JSON 부분만 추출
- 필요한 필드가 다 있는지 확인
- 각 필드의 타입이 맞는지 확인
- 예측 가능한 범위 내의 값인지 확인
- 다 통과하면
(True, data)반환, 출력단에서 키 값만 추출해서 일목요연하게 표시
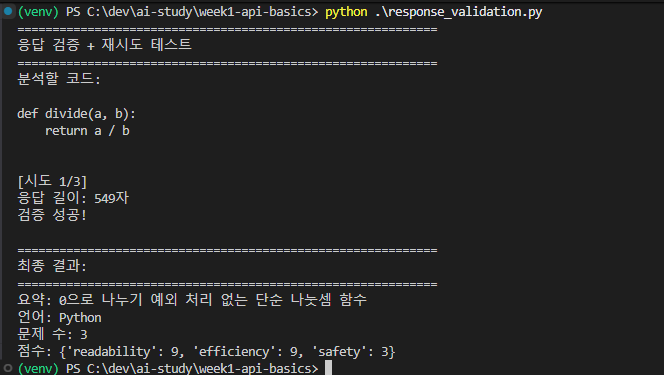
이번엔 첫 시도로 바로 통과했지만, 만약 잘못된 형식 / 범위 밖의 답을 줬다면 자동으로 재시도 했을 것이다.
이 패턴은 LLM 출력을 다운스트림 시스템 (DB, API, 다른 LLM 호출) 에 넘기기 전에 반드시 거쳐야 하는 단계. 형식 위반 한 번이 다음 시스템 전체를 망가뜨릴 수 있다.
회고
에러 핸들링 + 재시도 4단계 예제를 해보고 든 생각:
신뢰성·정확도를 갖춘 LLM 서비스를 만들려면 이 인프라가 가장 먼저 필요하다. 모델을 똑똑하게 만드는 것보다 응답이 어떤 상황에서도 일관되게 도착하게 만드는 게 우선.
특히 흥미로웠던 건 “내가 적용할 서비스에 대한 답변을 통제한다” 는 감각. LLM 응답이 형식을 어겼을 때 그냥 받아들이는 게 아니라, 내가 정의한 스키마에 강제로 맞추는 검증·재시도 사이클 을 거치게 한다. 이게 진짜 “LLM 을 코드에 통합한다” 는 의미인 것 같다.
더 공부해볼 것
1. Anthropic SDK 의 정확한 재시도 정책
- 기본
max_retries값 (Python SDK 기준) - 어떤 status code 가 재시도 대상인지의 정확한 목록
client.with_options(max_retries=N)로 재시도 횟수 커스터마이즈- Anthropic SDK errors and retries 공식 문서
2. Jitter 의 종류 — Full / Equal / Decorrelated
- Full jitter:
sleep = random(0, base * 2^attempt) - Equal jitter:
sleep = base * 2^attempt / 2 + random(0, base * 2^attempt / 2) - Decorrelated jitter: 직전 sleep 값을 기준으로 재계산
- AWS 공식 블로그 “Exponential Backoff And Jitter” 가 표준 레퍼런스
3. JSON 응답 강제하는 더 안전한 방법
- 프롬프트로 “JSON 으로 답해” 만 하는 건 약한 보장
- JSON mode / 구조화된 출력 (structured output) — 일부 모델은 스키마를 강제할 수 있음
- Tool Use 의 input_schema 를 응답 검증에 활용
- Pydantic + Instructor 라이브러리 — Python 에선 사실상 표준
4. Circuit Breaker 패턴
- 일정 횟수 이상 연속 실패하면 일정 시간 동안 호출 자체를 차단
- 호출처가 무한 재시도로 시간/비용 낭비하는 걸 방지
- 재시도와 짝꿍으로 같이 쓰는 패턴
- Netflix Hystrix, Resilience4j 등이 유명 구현체
5. 비용까지 고려한 재시도 전략
- 재시도할 때마다 토큰 사용 = 돈이 나간다
- “이 에러가 재시도할 만큼 값어치 있는가” 의 의사결정
- 사용자에게 “재시도 중” 알리는 UX
- 최종 실패 시 fallback 응답 (캐시 / 정적 응답 / 더 싼 모델)