오늘 주제는 RAG 직접 구현. Retrieval-Augmented Generation — 한국어로 “검색 증강 생성”. 용어만 봤을 땐 뭔 말인지 모르겠다. 직접 깎아보면서 안쪽을 봤다.
Table of contents
Open Table of contents
RAG 의 핵심 아이디어
대충 다이어그램으로 정리하면:

핵심은 “LLM이 모르는 문서를 외부에서 검색해서 컨텍스트로 같이 넣어준다”. 그 검색의 단위가 텍스트의 의미를 압축한 벡터(임베딩) 이고, 비교는 코사인 유사도 로 한다.
OpenAI API 키 발급 — Anthropic 은 임베딩 모델 없음
RAG 학습을 위해 OpenAI API 키를 발급 했다. Anthropic 토큰은 이미 결제했지만 임베딩 관련은 OpenAI 의 text-embedding-3-small 이 가성비 표준 이라고 한다.
- OpenAI 임베딩 = 시장 표준 (가장 많이 쓰이는 모델)
text-embedding-3-small: 1M 토큰 당 $0.02- 차원: 1536
왜인지는 모르겠는데 Anthropic 은 임베딩 모델을 안 만든다. Voyage AI, Cohere 같은 외부 모델을 쓰라고 권장. 이번 학습에선 OpenAI 로 진행.
1. 임베딩이 뭔지부터
일단 임베딩이 뭔지 감을 잡으려고 직접 호출해봤다. 텍스트를 벡터로 바꾸는 게 다.
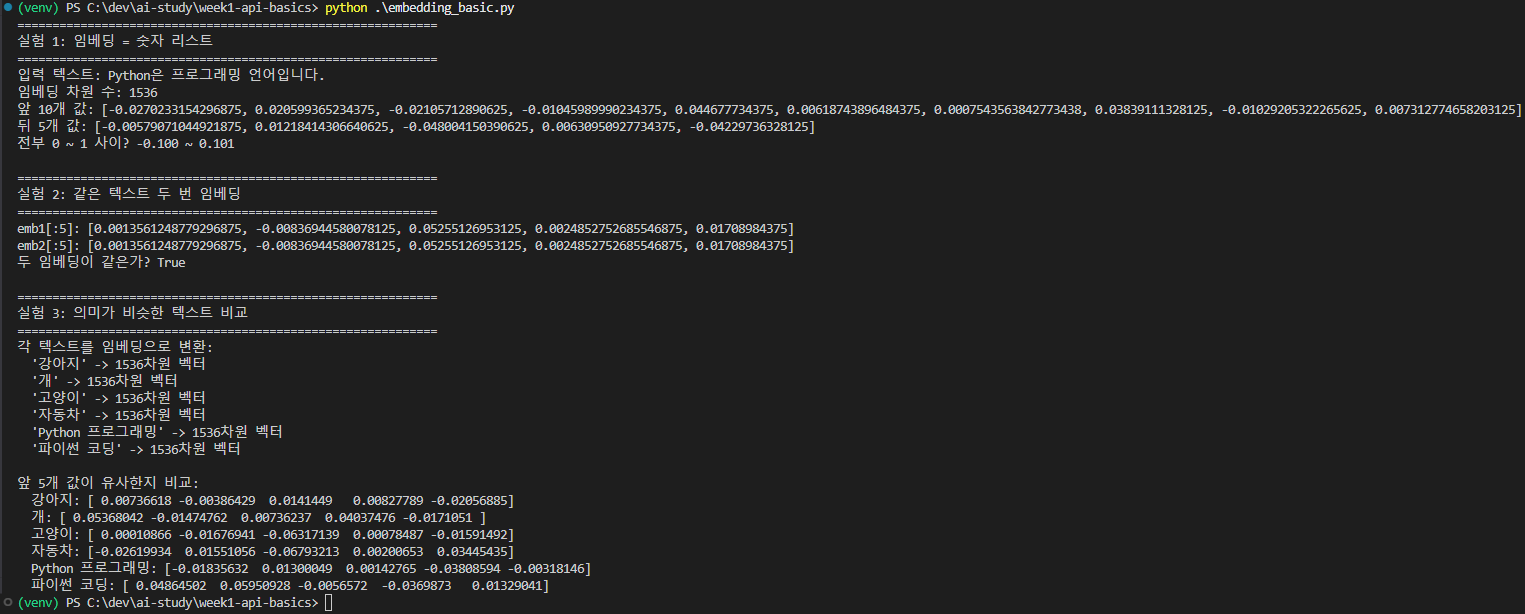
각 텍스트가 1536차원 벡터 로 변환된다.
근데 여기서 임베딩이 왜 필요한지 가 안 보였다. 단순히 벡터로 바꾸기만 해서는 텍스트끼리 얼마나 비슷한지 알 수가 없으니까. 다음 단계가 핵심.
2. 코사인 유사도 — 두 벡터가 얼마나 같은 방향인가
코사인 유사도 는 두 벡터가 얼마나 비슷한 방향 을 가리키는지 측정하는 방법. CNN 공부할 때 본 적 있는 것 같기도 한데 기억이 가물가물.
- 값 범위: -1 ~ 1
- 1 에 가까울수록 유사
- 0 근처면 무관
- -1 쪽 은 텍스트 임베딩에선 잘 안 나온다
첫 실험 — 의심스러운 결과
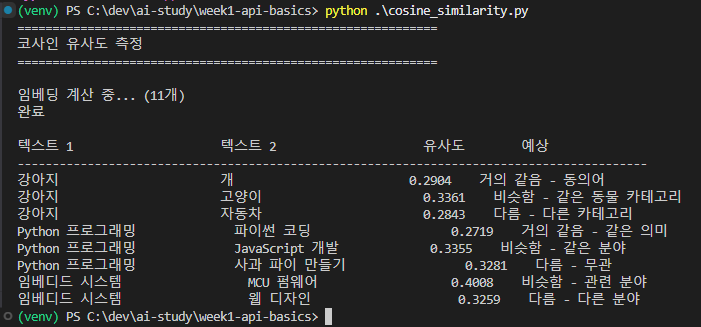
뭔가 이상하다. 0.2~0.4 사이에 임의로 배정된 것 같은 값. 전혀 유사도 기반이 아니었다.
“코드 실수인가?” 싶어서 전체를 복붙해서 다시 돌렸는데도 같은 결과. 에러 없는데 결과가 의심스러운 케이스 라서 굉장히 좋은 학습 케이스였다. 일시적인 모델 응답 문제인가도 의심했지만 그것도 아니었다.
가설: 단어 하나만 임베딩하면 모델이 의미 정보를 못 뽑을 수 있음. 그래서 좀 더 긴 텍스트로 다음 예제 진행.
3. Semantic Search — 한국어가 의외로 낮다
좀 더 긴 가짜 문서들 + 질문 리스트로 테스트.
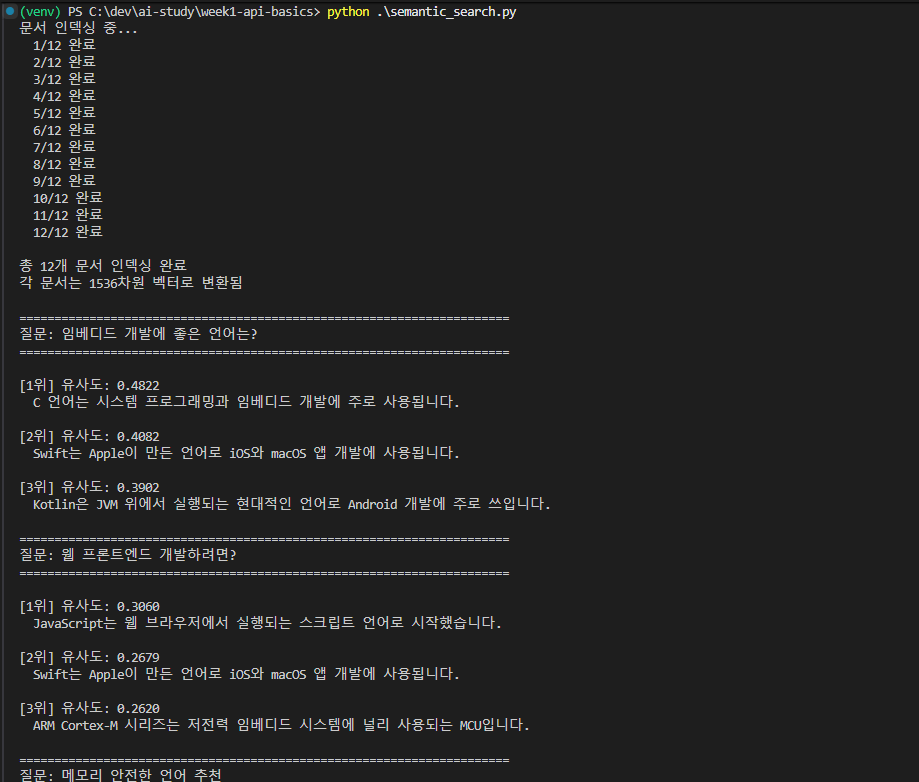
여전히 예상보다 적은 수치. 답변 품질을 의심하게 됐다. 보통 좋은 매칭은 0.6 ~ 0.8 정도가 일반적이라고 한다. 이번 결과는 1위는 맞췄지만 2위·3위는 부정확 + 1위 유사도도 0.30 ~ 0.50 아래.
가능한 원인 (메모해뒀다):
- 문서가 다 짧은 문장 이라서 의미 정보가 빈약
- 표면적 표현 유사성 때문에 진짜 의미 매칭이 어긋남
- 한국어 임베딩 자체의 한계 일 수도
세 번째가 마음에 걸려서 영어로 같은 실험 진행.
영어로 바꿔보니
확실히 유사도 절대값이 높고 매칭 품질도 좋았다. 한국어 임베딩의 한계가 진짜였다는 것.
그러면 영어로 임베딩하고 한국어로 응답 — Cross-lingual RAG
생각이 자연스럽게 이어졌다:
그러면 실제 서비스에서 영어로 임베딩한 다음 한국어로 번역해서 응답 하는 것도 방법 아닐까?
찾아보니까 이미 패턴이 있었다: Translation-based Retrieval 또는 Cross-lingual RAG.
| 장점 | 단점 | |
|---|---|---|
| 영어 임베딩 + 한국어 번역 | 임베딩 품질 높음 | 지연 시간 5배 증가 (번역 두 번 + 임베딩) |
| 한국어 특화 임베딩 (KoSimCSE 등) | 지연 시간 낮음 | 모델 품질 + 차원 / 호스팅 비용 trade-off |
운영 비용 자체는 생각만큼 안 늘어나는데 지연이 5배 라는 게 발목. 차라리 한국어 특화 임베딩 모델을 별도로 시도해보는 게 낫겠다 싶었다.
추가 관찰: 우연히 키워드가 비슷하면 그쪽이 더 유사하다고 잡는 경향이 있는 것 같기도 하다. 다만 긴 문서 라면 문맥 기반으로 잡힐 거라 검색이 더 잘 될 것으로 예상.
4. 청크 분할 — 왜 필요한가
코드: chunk_search.py
실전에서는 문서가 길다. 책 한 권, 논문 PDF, 코드베이스 전체. 전체를 한 번에 임베딩하면 의미가 흐려진다.
직관 — 임베디드 책 한 권을 임베딩하면?
각 장의 평균은 결국 “임베디드 개발” 정도가 된다. 그래서 “RTOS 도입은 언제 해야 해?” 라고 물어도 거기에 맞는 벡터를 못 찾는다.
→ 청크로 잘라서 임베딩해야 RTOS 관련 청크가 따로 잡힌다.

이번 예제도 유사도 절대값은 크지 않았지만 1순위 답변은 다 맞게 매칭.
청크 사이즈 trade-off
| 청크 사이즈 | 정밀 매칭 | 맥락 | 노이즈 |
|---|---|---|---|
| 작음 | ✅ | ❌ 손실 | ❌ 없음 |
| 큼 | ❌ | ✅ 유지 | ⚠ 늘어남 |
일반적 권장: 256 ~ 512 토큰 (한국어 기준 약 500 ~ 1000자).
회고
오늘 한 줄로 정리하면:
임베딩은 그냥 벡터 변환. 의미는 코사인 유사도로 측정. 긴 문서는 청크로 잘라야 한다.
가장 인상 깊었던 건 두 가지:
-
코드 에러가 없는데 결과가 이상한 케이스 — 모델 출력 자체가 의심스러울 때 어떻게 디버깅할지 감을 잡는 좋은 케이스였다. 단어 하나 vs 문장 길이, 한국어 vs 영어 같이 변수를 바꿔보는 디버깅 패턴.
-
한국어 임베딩의 약점이 실제로 관찰됨 — 막연히 “한국어가 약하다더라” 가 아니라 0.3 vs 0.7 같은 숫자 차이로 직접 확인. 영어 임베딩 + 번역(Cross-lingual RAG) 이 왜 패턴이 됐는지 이해.
더 공부해볼 것
1. 임베딩의 원리 (작성자 의문)
- Transformer 가 텍스트를 벡터로 만드는 메커니즘 — 토큰 임베딩 → 어텐션 → 풀링
- Word2Vec / GloVe → BERT / Sentence-BERT → OpenAI Ada / text-embedding-3 의 진화
- 차원의 의미 — 1536 차원이 각각 무엇을 표현하는가 (사실은 해석 불가, 학습으로 결정됨)
- 영상이든 논문이든 깊이 한 번 정리해두고 싶음
2. 한국어 특화 임베딩 모델
- KoSimCSE / KoSBERT — 한국어 sentence embedding 의 사실상 표준
- multilingual-e5-large — 다국어 모델 중 한국어 성능 양호
- Voyage AI multilingual — 상용 옵션
- 한국어 임베딩 모델 벤치마크 (KLUE-STS 등) 에서 OpenAI 와 비교
3. 벡터 DB
- pgvector (Postgres + 벡터 확장) — Supabase 가 기본 지원
- Pinecone / Weaviate / Chroma / Qdrant — 전용 벡터 DB
- HNSW vs IVF 인덱스 알고리즘
- 단순히 numpy 로 코사인 유사도 계산 vs 벡터 DB 의 ANN 검색 trade-off
4. 청크 분할 전략
- Fixed-size chunking — 단순히 N 토큰씩 자르기
- Recursive Character Splitter — 문단 → 문장 → 단어 순서로 깨기 (LangChain 표준)
- Semantic Chunking — 의미 경계에서 자르기 (느리지만 품질↑)
- Sliding Window + Overlap — 청크 간 맥락 보존
- 청크 사이즈 + overlap 의 최적값 찾는 실험 방법
5. Hybrid Search — 키워드 + 의미
- 벡터 검색만으로는 고유명사 / 정확한 코드 / 오타 같은 게 잘 안 잡힘
- BM25 (전통적 키워드 검색) + 벡터 검색 결합 = Hybrid
- Reciprocal Rank Fusion (RRF) — 두 검색 결과 순위를 합치는 방법
- Elasticsearch, Weaviate 등이 hybrid 를 1급으로 지원